Optimiser MySQL
Noter ce cours : 
Introduction
MySQL est très souvent utilisé pour concevoir des sites dynamiques. Le problème se pose lorsque le site en question devient de plus en plus visité (ou alors lorsqu'il comprend des scripts habituellement gros consommateurs en MySQL lorsqu'ils ne sont pas optimisés, tels que certains forums par exemple). Il arrive alors souvent que le serveur ne supporte plus la charge imposée par les clients. Au mieux vous aurez une erreur de max_user_connections résolvable assez facilement si vos requêtes sont mal conçues, au pire vous pouvez avoir un plantage du serveur MySQL qui n'arrive plus à répondre face aux requêtes qui lui sont adressées.
Quelles solutions adopter ?
Face à ces problèmes il existe plusieurs solutions. De nombreux webmasters préfèrent directement changer le serveur (ou augmenter ses capacités) sans se poser de questions. Il est évident qu'avant de changer le serveur pour un plus puissant, il faut regarder si les requêtes MySQL sont bien conçues au lieu de foncer sur un changement de matériel sans réflexion préalable, d'une part car optimiser un script est "gratuit" comparé à l'achat ou à l'upgrade d'un ou de plusieurs serveurs, d'autre part car face à un script très mal optimisé, l'augmentation des capacités matérielles a une limite. Nous allons donc tout d'abord dans cet article présenter les quelques erreurs pouvant être simplement réparées en ajoutant un index ou en modifiant une ou deux lignes dans un script PHP, puis nous passerons au "lourd", à savoir des propositions d'amélioration de structures de table MySQL en fonction de cas concrets. Nous supposerons que les champs de vos tables MySQL utilisent des types appropriés à leur contenu. Pour choisir le bon type de champ en fonction des données qu'il sera amené à contenir, vous pouvez consulter ce lien : Types de données - MySQL.
Et avec un autre SGBDR ?
Si vous utilisez un autre SGBDR (Système de gestion de base de données relationnelles) comme PostgreSQL ou encore Microsoft SQL Server, les règles que vous allez voir ci-dessous ne seront pas forcément fonctionnelles (clause LIMIT notamment). Par contre, la plupart de ces règles s'appliquent à tous les SGBDR. N'hésitez donc pas à les mettre en pratique ;)
Choisir les champs à récupérer
Nous allons commencer par traiter le problème des requêtes de sélection. Une règle d'or lorsque l'on conçoit une requête MySQL : ne ramener que ce dont on a besoin. Plus le nombre de données à ramener sera faible, plus ce sera rapide (à requête équivalente bien entendu). Prenons l'exemple d'une structure de table destinée à stocker des informations sur les membres d'un site, cette table s'appellera "membres" :

Pour effectuer nos requêtes MySQL, nous passerons par PDO, qui est une classe d'abstraction disponible dans les dernières versions de PHP. Voici un code exemple pour effectuer une requête dans la table membres, elle même située dans la base de données nommée mabase :
Si nous souhaitons récupérer simplement la liste des pseudos de tous les membres, une solution sale consiste à faire une requête de ce type :
SELECT * FROM membres
Ensuite on récupère via PHP tous les pseudos :
<?php
class sql
{
private $connexion_sql;
function __construct()
{
$this->connexion_bdd = new PDO('mysql:host=localhost;dbname=mabase', 'root', '');
$this->connexion_bdd->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
}
public function requete($requete)
{
$prepare = $this->connexion_bdd->prepare($requete);
$prepare->execute();
return $prepare;
}
}
$sql = new sql();
$req = $sql->requete('SELECT * FROM membres');
while ($r = $req->fetch())
{
echo $['pseudo'],'<br>';
}
?>
Cette solution n'est pas optimisée car le serveur MySQL renvoie tous les champs de la table à PHP (le * dans la requête signifie "tous les champs"), alors que nous n'avons besoin que du champ "pseudo". D'une manière générale, et même si vous avez besoin de tous les champs de votre table, n'utilisez jamais de SELECT * mais indiquez toujours la liste des champs dont vous avez besoin.
Voici une solution optimisée au niveau de la requête :
<?php
$sql = new sql();
$req = $sql->requete('SELECT pseudo FROM membres');
while ($r = $req->fetch())
{
echo $['pseudo'],'<br>';
}
?>
Fermer la connexion
Pour pouvoir effectuer des requêtes, PHP ouvre une connexion au serveur SQL. Cette connexion consomme des ressources processeur et de la mémoire. Elles sont par conséquent limitées.
Lorsque vous n'avez plus besoin de la connexion SQL ou MySQL, il est impératif de la fermer, sous peine d'avoir des erreurs de "max_user_connections" ou d'autres erreurs avec d'autres SGBDR. Cette erreur signifie que vous avez dépassé le nombre de connexions maximales à MySQL autorisées simultanément. Avant de toucher aux fichiers de configuration, il serait judicieux d'optimiser ses scripts. Pour fermer la connexion on utilise la fonction closeCursor() avec PDO, ou mysql_close() avec les anciennes fonctions mysql_* de PHP. Voici un exemple de script mal conçu au niveau de la connexion :
<?php
$sql = new sql();
$req = $sql->requete('SELECT pseudo FROM membres');
while ($r = $req->fetch())
{
echo $['pseudo'],'<br>';
}
?>
On constate sur ce code qu'il n'y a aucune fermeture de la connexion ouverte. Il faut donc fermer la connexion proprement après avoir effectué la dernière requête. Les fonctions de "fetch" ne nécessitent pas d'avoir la connexion ouverte avec MySQL uniquement, et sans utiliser PDO.
Il est important de signifier que la connexion sera automatiquement fermée dès la fin du script, inutile donc de mettre un closeCursor() ou un mysqlClose() à la dernière ligne de votre script.
Voici donc le code optimisé :
<?php
$sql = new sql();
$req = $sql->requete('SELECT pseudo FROM membres');
while ($r = $req->fetch())
{
echo $['pseudo'],'<br>';
}
$req->closeCursor();
//Votre code qui n'utilise plus la connexion SQL
?>
La clause LIMIT
Cette clause très particulière est très souvent utilisée en cas de besoin de paginer les résultats (forum par exemple). C'est entre autres elle qui est responsable de la lenteur des forums dont je vous parlerai plus bas dans cet article. La clause LIMIT permet de limiter le nombre d'enregistrements retournés par MySQL. Reprenons notre requête d'affichage des pseudos des membres.
Plus le nombre de membres va augmenter, plus il va devenir important de fractionner par pages l'affichage de la liste des membres sous peine d'avoir des milliers de membres à afficher d'un coup (ce qui n'est pas vraiment recommandé pour le serveur web, ni pour le visiteur qui devra télécharger la page générée...).
Si nous souhaitons afficher les 20 premiers membres, nous pourrons utiliser une clause LIMIT, la requête sera celle-ci :
SELECT pseudo FROM membres LIMIT 20 OFFSET 0
- Le mot OFFSET sert à indiquer le nombre de lignes que l'on sautera avant de retourner le nombre de lignes de notre choix.
- Le mot LIMIT suivi d'un nombre indique le nombre de lignes à retourner.
Si nous souhaitons récupérer les 20 membres à partir du 40ème, nous procèderons donc comme ceci :
SELECT pseudo FROM membres LIMIT 20 OFFSET 40
Le gros problème de cette requête (avec MySQL) est qu'elle va sélectionner toutes les valeurs de la table avant de "faire le tri" à savoir avant d'envoyer les 20 enregistrements à PHP. Or sélectionner des milliers d'enregistrements est très, très long. C'est pour ça que les forums peu optimisés fonctionnent rapidement à leur ouverture, les performances se dégradant nettement au fur et à mesure que les membres postent des messages.
Comment optimiser LIMIT
La table membres que nous avons crée contient un champ nommé id_membre en AUTOINCREMENT. Ce type de champ nécessite un index pour pouvoir être appliqué à une table. Nous allons voir ci dessous ce qu'est un index, sachez qu'il accélère, quand il est bien conçu, les requêtes de sélection. Chaque membre aura donc un numéro différent, le numéro du prochain membre à s'inscrire sera incrémenté par rapport au précédent. Nous pouvons donc utiliser ce champ pour notre requête de sélection. Nous allons supprimer la clause LIMIT et utiliser un BETWEEN à la place. Le BETWEEN permettra de recueillir uniquement les valeurs que nous souhaitons sans parcourir toute la table inutilement. La requête devient ceci (il est très important d'avoir un index sur le champ id_membre sous peine de n'obtenir que de faibles gains) :
SELECT pseudo FROM membres WHERE id_membre BETWEEN 40 AND 60
Cette requête permettra de récupérer 20 membres (60-40 = 20) tous situés après le 39ème membre (car le premier id du membre qui sera récupéré portera la valeur 40). Le seul inconvénient de cette méthode est que si vous supprimez par exemple un membre dont l'id est situé entre ces deux valeurs, vous ne récupèrerez plus que 19 enregistrements au lieu de 20. Le jeu en vaut la chandelle à mon avis, et votre serveur vous remerciera. Pour les serveurs non compatibles avec le BETWEEN, sachez que la requête ci-dessus est équivalente à ceci :
SELECT pseudo FROM membres WHERE id_membre > 40 AND id_membre < 60
Les index :
Imaginez un livre. Plus le livre contient de pages, plus vous allez mettre du temps à rechercher l'information désirée. C'est pour cela qu'il existe en général une table des matières au début ou à la fin du livre. Cette table vous permet d'accéder très rapidement sans feuilleter le livre à l'information que vous recherchez.
Un index en MySQL fonctionne sur ce principe, à savoir qu'il va vous permettre d'accélérer nettement (une requête 10 fois plus rapide n'est pas un cas exceptionnel dans le cas d'un index bien utilisé) vos requêtes de sélection. Il faut cependant être conscient qu'un index ralentit les requêtes d'insertion ou de mise à jour (dans une moindre mesure) de donnés, il faut donc les utiliser avec parcimonie. Indexer tous les champs d'une table MySQL est stupide.
Nous allons rajouter un champ date_inscription à notre table de membres, puis nous utiliserons une requête type pour récupérer les membres étant inscrits depuis moins d'une semaine. Voici la nouvelle structure de la table :
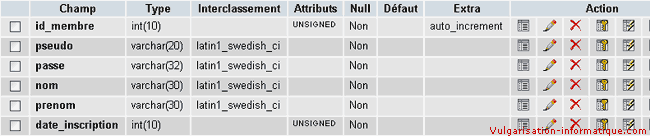
Une requête type consistant à récupérer les membres inscrits depuis moins de 7 jours consiste à faire ceci :
<?php
$sql = new sql();
$req = $sql->requete('SELECT pseudo FROM membres WHERE date_inscription >'.time()-7*3600*24);
while ($r = $req->fetch())
{
echo $['pseudo'],'<br>';
}
$req->closeCursor();
?>
Pensez également aux index multi colonnes. Prenons l'exemple de la requête suivante :
SELECT pseudo FROM membres WHERE date_inscription > X AND id_membre BETWEEN 40 AND 60
Il est judicieux de créer dans ce cas un index sur deux colonnes (date_inscription et id_membre). Pour ce faire, dans PHPMyadmin, regardez la zone "créer une clé sur ... colonnes". Mettez "2" dans le nombre de colonnes et cliquez sur Exécuter. Vous avez accès à ceci :
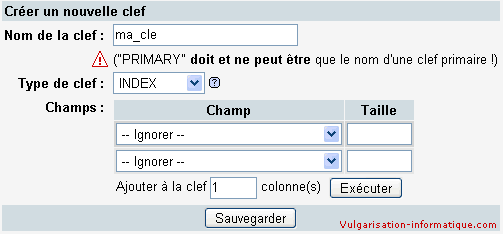
Dans la zone "Type de clé" choisissez "Index". Choisissez ensuite comme premier champ "id_membre" et ensuite "date_inscription", puis cliquez sur "sauvegarder". Ne vous occupez pas de la colonne "taille" de de PHPMyadmin, cette colonne ne sert (en gros) que pour les index sur les champs de caractères (VARCHAR entre autres). L'avantage est double pour les champs de ce type : Si vous mettez "2" dans la zone "taille", l'index indexera les deux premiers caractères de chaque mot. Il serait peu recommandé de mettre la longueur maximale du champ dans cette zone car vous perdrez en performances et en espace disque.
Il est important de souligner que les index sur les champs de type numériques sont plus rapides à traiter par MySQL. Ainsi, il est peu recommandé d'utiliser dans les clauses WHERE les champs de type chaînes de caractères. Pour sélectionner des informations sur un membre, on n'utilisera donc pas son pseudo. La requête suivante n'est pas optimisée (même si un index est placé sur le champ pseudo) :
SELECT nom,prenom FROM membres WHERE pseudo = 'webmaster'
On préfèrera la requête suivante :
SELECT nom,prenom FROM membres WHERE id_membre = X
D'une part, vous gagnerez en performances, mais d'autre part vous gagnerez en espace disque car on a été obligé d'indexer le champ id_membre (vu que c'est un champ AUTOINCREMENTE, il doit être obligatoirement accompagné d'un index). Donc au lieu d'avoir deux index (l'un sur le champ id_membre et l'autre sur le champ pseudo) nous n'en avons qu'un, ce qui cumule les avantages que ce soit en terme de performances (en écriture ou en lecture) ainsi qu'en espace disque (indexer un champ de type "chaîne" prend plus de place).
Les tables de type HEAP (ou MEMORY)
Pour des données peu sensibles (compteur de connectés, système personnel de sessions utilisant MySQL, etc...) vous pouvez utiliser les tables de type HEAP (ou MEMORY selon les versions de MySQL). Ce type de table est très particulier puisque les données sont stockées dans la mémoire vive. Il n'y a ainsi plus d'accès au disque dur pour récupérer les données ce qui augmente nettement les performances.
Attention cependant, ce type de tables n'est pas à utiliser pour stocker des données sensibles, car en cas de redémarrage de MySQL ou/et de plantage du serveur, les données seront perdues.
Utiliser la clause EXPLAIN
Cette clause rajoutée aux requêtes de type SELECT va vous permettre d'auditer les performances de vos requêtes. Lorsque vous rajoutez le mot EXPLAIN devant votre requête de type SELECT (dans PHPMyadmin) vous allez pouvoir avoir quelque chose qui ressemble à ceci (avec des valeurs pouvant varier bien entendu) :

On constate qu'il y a plusieurs colonnes résultant de cette action. Voici une explication des colonnes retournées :
- Id : le numéro de la requête SELECT dans la requête globale.
- Select_type (quelques valeurs que peut prendre cette colonne) :
- SIMPLE : SELECT simple (sans UNION ni sous- requêtes).
- SUBQUERY : Premier SELECT d'une sous- requête.
- Table : Table utilisée.
- Type : type de jointure utilisée. Voici quelques types de jointures, du plus rapide au plus lent :
- system : Cas rare, lorsque la table comporte une seule ligne (jointure de type CONST).
- const : la table possède au plus une seule ligne répondant à la valeur demandée qui sera lue dès le début de la requête. Ce type de jointure est très rapide.
- eq_ref : C'est le meilleur type de jointure possible. Ce type est utilisé lorsque toutes les parties d'un index sont utilisées par la jointure. L'index doit être de type UNIQUE ou PRIMARY KEY.
- ref : Si MySQL ne peut pas retourner une seule ligne en fonction de la jointure, toutes les lignes ayant des valeurs correspondantes seront lues par MySQL.
- ref_or_null : Comme le type ref, mais un coût supplémentaire pour les recherches ayant des valeurs NULL comme cas possible. Il est d'ailleurs recommandé de mettre vos champs en NOT NULL pour accélérer les traitements.
- range : seules les lignes dans un intervalle donné seront lues dans l'index.
- index : même chose que ALL, seul l'index est utilisé ce qui peut accélérer légèrement les performances étant donné que la taille du fichier d'index est généralement plus faible que celle des données.
- ALL : à bannir, une analyse complète de la table est faite.
- Possible_keys : Cette colonne indique quels index MySQL va pouvoir choisir pour trouver les lignes correspondant à la requête.
- Key : Cette colonne indique l'index que MySQL aura finalement utilisé pour trouver les lignes correspondant à la requête.
- Key_len : Cette colonne indique la taille de la clé utilisée par MySQL.
- Ref : Cette colonne indique quelle colonne ou quelles constantes sont utilisées pour sélectionner les lignes de la table
- Rows : Estimation du nombre de lignes à parcourir avant d'obtenir le résultat. Plus cette valeur est faible, meilleures seront les performances.
- Extra : Cette colonne contient quelques informations supplémentaires très utiles sur la procédure de résolution de la requête. Voici quelques informations utiles :
- Using filesort : MySQL va avoir besoin d'effectuer un second passage pour trier les lignes. Sur un petit nombre de lignes retournées ça peut convenir, mais essayez d'éviter d'obtenir des Usign filesort avec 1000 enregistrements retournés par exemple...
- Using Index : MySQL n'ouvre pas la table et lit directement les informations dans l'index. C'est très rapide et devrait être présent le plus possible dans vos requêtes.
- Using Temporary : MySQL va créer une table temporaire pour contenir le résultat. Cela se passe généralement en cas d'utilisation d'une clause ORDER BY sur une colonne différente de celle utilisée pour la clause GROUP BY. Cela nuit aux performances.
- Using Where : Une clause Where sera utilisée pour limiter le nombre de lignes retournées.
Cas particulier des forums (gratuits ou payants) disponibles en téléchargement
De nombreux forums (payants ou gratuits) tel que PHPBB ou encore IPB, Simple Machines Forum, etc... sont très peu optimisés ce qui fait que dès que les forums en question deviennent fréquentés (avec un nombre de messages conséquent) le temps de génération de chaque page augmente très rapidement en parallèle.
Ces forums peuvent ne pas supporter une forte charge qui pourrait leur être imposée. Face à ce problème, il n'y a généralement (après avoir désactivé toutes les fonctionnalités inutiles gourmandes proposées) pas d'autre solution que de changer le serveur, car reprogrammer entièrement de tels forums est une pure perte de temps (par où commencer ? il y a tellement de travail...). Le problème de ces forums est qu'ils utilisent pour sélectionner une tranche de topics (ou de messages) la clause LIMIT dans leurs requêtes MySQL (mal conçues).
La solution ultime consiste à concevoir soi-même son propre forum. Bien sûr cela demande du temps et de bonnes connaissances en optimisation PHP et MySQL (sous peine de refaire les mêmes erreurs). Il existe cependant de bons forums gratuits open source. Je peux vous en citer un : FluxBB. Ce forum est léger, personnalisable et disponible en français.
Une bonne solution pour réaliser son forum personnel est d'utiliser les requêtes de type BETWEEN. Il faudra généralement pour cela rajouter un ou deux champs supplémentaires (deux dans la table des topics et un dans la table des messages) si vous avez des sous catégories. Sinon un seul champ par table suffira. Ce champ servira de "marqueur de position" et c'est sur ce champ que sera fait le BETWEEN, ce qui fait que seuls les topics de la page désirée seront scannés, le forum tiendra ainsi la charge même avec plusieurs milliers de topics/messages.